
系统环境:Windows7
任务要求:爬取URL + 爬取里面的新闻内容 + 入库
项目软件地址

1、我们首先要有一个URL列表,有了列表我们才能深度去挖掘新闻的内容
使用cl 命令收集要爬取的内容:
C:\Users\ssHss\Desktop\Jar包\ImageTemp>java -jar Crawler1.0.3.jar -cl http://news.qq.com/ -cq "div[class=Q-tpWrap]"
-cl http://news.qq.com/
-cq "div[class=Q-tpWrap]" 就是样式代码 <div class="Q-tpWrap" style:"xxsxxs:da;dadsad;sad;"><a href="x">x</a></div>
提取规则 -cq 后面的参数
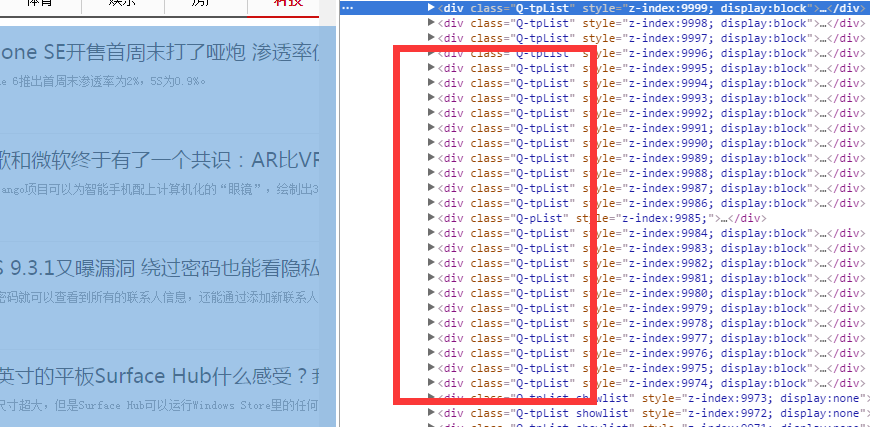
唉呀妈呀,我们爬取的里面怎么还有各种不一样的代码呢,ヾ(。`Д´。). ok,我们加format参数,哈哈,这样写代码会比较安全一点。 -format 特征
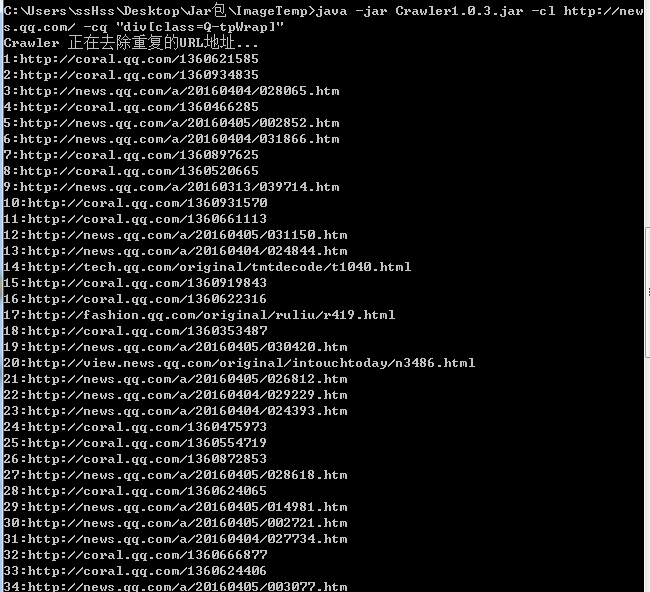
通过爬取的我们发现 news.qq.com/a/ 是新闻共有的一个URL特征
我们加特技 -fromat "news.qq.com/a/"

加File,我们生成URL到本地路径中 -input localpath 即可

第一步我们完成了 URL的收集
2、深度爬取内容 使用ci命令
加载本地URLlist文件,进行爬取


我看了下内容,我把neirong抽取写错了,改成div[class=db]就好了。
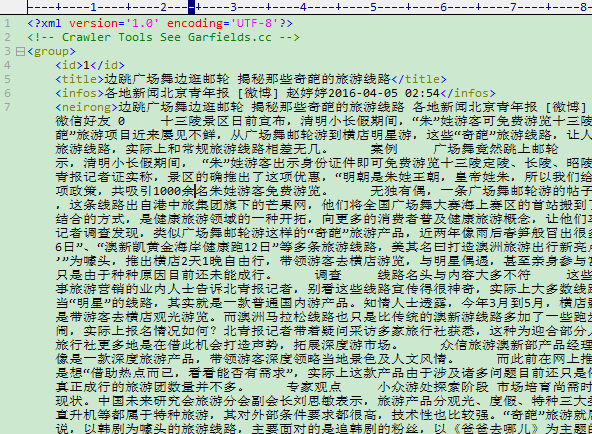
3、导入数据库
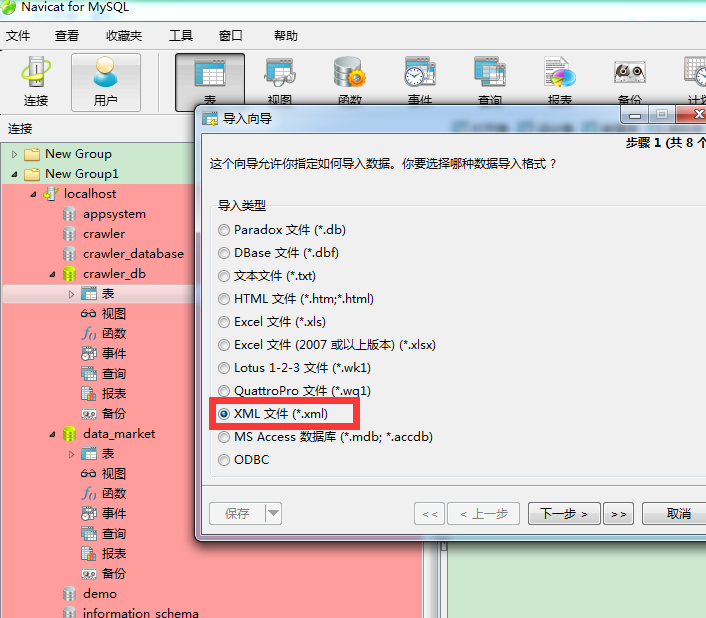
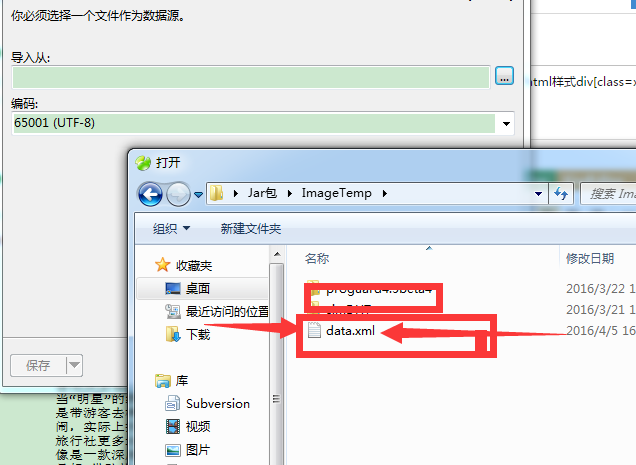

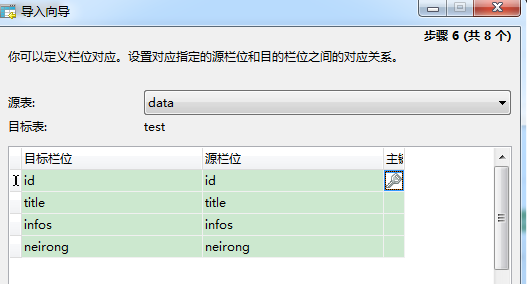

完成了